
The simplest regression algorithm?
This post was inspired by Section 2.3 of the excellent (and free) textbook, The Elements of Statistical Learning (1). The example analyses were done with scikit-learn (2). The data analyzed was taken from Kaggle (3).
Try for a moment to forget everything that you’ve learned about statistical modeling and machine learning. Now, consider the problem of predicting a quantity, $y$, associated with a set of descriptors $\overline{x}$ given some examples ${(\overline{x}, y)}$ (a training set). $y$ is a scalar and $\overline{x}$ is a list of descriptors, which we will take to be real-valued numbers for simplicity.
One common approach to predicting $y$ is to assume a particular kind of relationship between $y$ and $\overline{x}$. Perhaps the simplest and most common assumption of this type is that $y$ is related to $\overline{x}$ such that
where $\beta_0$ and ${\beta_i}$ are adjustable parameters that are determined by minimizing a measure of error in the predictions over the training set. This approach, known as linear regression may have been the first approach to prediction of scalar values that you learned about, but is this what you would have come up with if you were inventing statistical modeling for the first time?
The application of linear regression entails a fairly strong assumption, namely that there’s a linear relationship between the predictors (or descriptors) and the value to be predicted. The documented success of linear models in practice is very often all the justification that one needs for trying linear regression when you come upon a new prediction problem. But is there an even simpler assumption that you could have (or would have) made if you didn’t know about the successes of linear models?
It would seem natural to assume that sets of descriptors $\overline{x}$ that are in some sense “close” would have similar values of $y$. This is the basic idea behind nearest neighbors regression. Nearest neighbors regression is simpler than linear regression in the sense that it is also true for linear regression that small changes in $\overline{x}$ lead to small changes in $y$, but nearest neighbors regression does not assume any particular form of $y(\overline{x})$. So if nearest neighbors regression does not assume a linear model, then how does it work?
The predictions by nearest neighbors regression of $y$, denoted $\hat{y}$, for the descriptors $\overline{x}$, are given by
In words, the above equation says
Our prediction of $y$ for a set of descriptors $\overline{x}$ is the average of the values $y$ for the $k$ nearest neighbors of the point $\overline{x}$.
That is a strikingly simple and natural way of performing predictions. As with most methods, however, the devil is in the details. In particular, we need
- a way of choosing $k$
- a measure of distance between points $\overline{x}$
There are many ways to handle these problems, but a few of the simplest are to (1) train using different values of $k$ and find the minimum value of an error measure on a test set and (2) use the Euclidean distance (probably) after scaling the descriptors).
Let’s see how some of these ideas work in practice. We will be looking at some housing price data from King’s County that can be downloaded from Kaggle (3).
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv("kc_house_data.csv")
There are some houses that appear more than once in the set. For illustration purposes, let’s eliminate the duplicate entries. You’ll see why below.
df = df.drop_duplicates(subset=["lat", "long"])
df.columns
Index(['id', 'date', 'price', 'bedrooms', 'bathrooms', 'sqft_living',
'sqft_lot', 'floors', 'waterfront', 'view', 'condition', 'grade',
'sqft_above', 'sqft_basement', 'yr_built', 'yr_renovated', 'zipcode',
'lat', 'long', 'sqft_living15', 'sqft_lot15'],
dtype='object')
It looks like we have a bunch data types to work with, but to simplify things let’s look only at the latitude and longitude columns. These variables will lead to a natural sense of “closeness” and have the same units, so we don’t have to worry about scaling them before computing the distances.
X = df[["lat", "long"]]
X.head()
| lat | long | |
|---|---|---|
| 0 | 47.5112 | -122.257 |
| 1 | 47.7210 | -122.319 |
| 2 | 47.7379 | -122.233 |
| 3 | 47.5208 | -122.393 |
| 4 | 47.6168 | -122.045 |
y = df["price"]
y.head()
0 221900.0
1 538000.0
2 180000.0
3 604000.0
4 510000.0
Name: price, dtype: float64
Split the data into train and test sets.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
Import scikit-learn’s nearest neighbor regression function and fit the training data. For now, we will fit using the limiting case of $k=1$, i.e., we will assume that the price of the house is equal to the price of the nearest neighbor in the training set.
from sklearn.neighbors import KNeighborsRegressor
neigh = KNeighborsRegressor(n_neighbors=1, algorithm='brute')
neigh.fit(X_train, y_train)
KNeighborsRegressor(algorithm='brute', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=1, p=2,
weights='uniform')
Make the predictions $\hat{y}$ for the training and test sets.
y_hat_train = neigh.predict(X_train)
y_hat_test = neigh.predict(X_test)
Compute the root mean squared error for the training and test sets.
rmse_train = np.sqrt(np.mean((y_train - y_hat_train)**2))
rmse_test = np.sqrt(np.mean((y_test - y_hat_test)**2))
rmse_train, rmse_test
(0.0, 289670.225389659)
The root mean squared error over the training set is zero! Think about how the prediction is being done. When it comes time to predict the price of a house in the training set, it looks for the closest house in the training set and uses the price of that house as the predicted price. But when you are making predictions on the training set, the closest house is, of course, the house itself!
Now you can understand why we eliminated the duplicate houses in the data set. If the same house shows up twice and sold for two different prices, then even on the training set the RMSE would not be zero. That might be fine in practice, but I wanted to illustrate the above point.
Let’s try a few different values of $k$ to see what “size” neighborhood works best on the training set.
rmses_train = []
rmses_test = []
k_range = range(1,50)
for k in k_range:
neigh = KNeighborsRegressor(n_neighbors=k, algorithm='brute')
neigh.fit(X_train, y_train)
y_hat_train = neigh.predict(X_train)
y_hat_test = neigh.predict(X_test)
rmse_train = np.sqrt(np.mean((y_train - y_hat_train)**2))
rmses_train.append(rmse_train)
rmse_test = np.sqrt(np.mean((y_test - y_hat_test)**2))
rmses_test.append(rmse_test)
plt.style.use('fivethirtyeight')
plt.figure(figsize=(8,6))
plt.plot(k_range, rmses_train, label="train")
plt.plot(k_range, rmses_test, label="test")
plt.legend()
<matplotlib.legend.Legend at 0x1a20ee7e80>
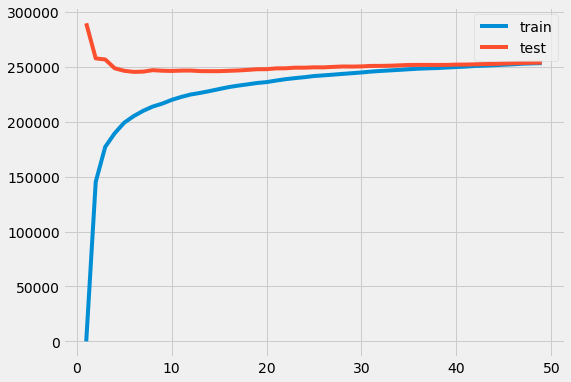
The test error drops initially when going from 1 to about 5 neighbors and then remains relatively constant. As the number of neighbors $k$ approaches 50, the testing and training error are nearly the same.
You may feel as though it would be more natural to average over prices over a specific radius rather than a fixed number of neighbors. There’s a method for that! Note that, below, the radius has the same units as the distance that is being computed, in this case degrees latitude/longitude.
from sklearn.neighbors import RadiusNeighborsRegressor
rmses_train = []
rmses_test = []
r_range = np.arange(0.001,0.1,0.005)
for r in r_range:
neigh = RadiusNeighborsRegressor(radius=r, algorithm='brute')
neigh.fit(X_train, y_train)
y_hat_train = neigh.predict(X_train)
y_hat_test = neigh.predict(X_test)
rmse_train = np.sqrt(np.mean((y_train - y_hat_train)**2))
rmses_train.append(rmse_train)
rmse_test = np.sqrt(np.mean((y_test - y_hat_test)**2))
rmses_test.append(rmse_test)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
/Users/npschafer/anaconda/lib/python3.6/site-packages/sklearn/neighbors/regression.py:327: UserWarning: One or more samples have no neighbors within specified radius; predicting NaN.
warnings.warn(empty_warning_msg)
The warnings here are telling us an important story about the disadvantage of using a radius-based predictor: sometimes there are no houses in the training set to make predictions on a house in the test set. Those cases are discarded when computing the error metrics, but in practice this would be a problem.
plt.figure(figsize=(8,6))
plt.plot(r_range, rmses_train, label="train")
plt.plot(r_range, rmses_test, label="test")
plt.legend()
<matplotlib.legend.Legend at 0x1a205576d8>
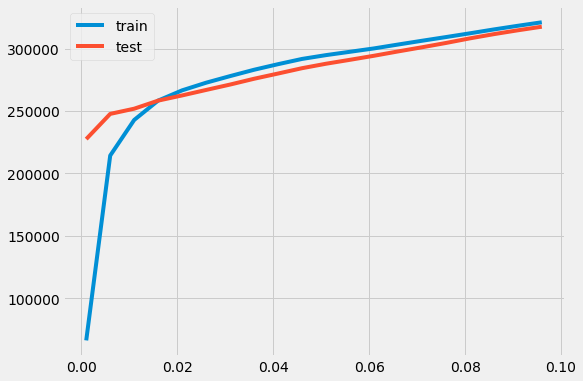
These simple models are certainly not yielding very precise predictions of housing prices, but how do the predictions obtained by nearest neighbor regression compare to the predictions that would be obtained by naive application of linear regression to this problem?
from sklearn.linear_model import LinearRegression
reg = LinearRegression().fit(X_train, y_train)
y_hat_train = neigh.predict(X_train)
y_hat_test = neigh.predict(X_test)
rmse_train = np.sqrt(np.mean((y_train - y_hat_train)**2))
rmse_test = np.sqrt(np.mean((y_test - y_hat_test)**2))
rmse_train, rmse_test
(371707.9407400356, 369733.33918304584)
Perhaps unsurprisingly, nearest neighbors regression is doing better than linear regression. This example was concocted such that this would be the case. Nonetheless, this comparison illustrates an important point, namely that thinking about how variables might be related to each other before choosing a particular machine learning model can help quite a bit. Can you see why would be a better model than for the prediction of housing prices ($y$) given the latitude and longitude ($\overline{x}$)?